All Categories
Featured
Table of Contents
What is important in the above contour is that Degeneration gives a higher value for Information Gain and therefore create even more splitting contrasted to Gini. When a Choice Tree isn't complex sufficient, a Random Forest is normally made use of (which is absolutely nothing more than multiple Choice Trees being grown on a subset of the data and a last majority ballot is done).
The variety of clusters are identified making use of an arm joint curve. The variety of clusters may or might not be very easy to find (especially if there isn't a clear twist on the contour). Additionally, understand that the K-Means formula maximizes in your area and not globally. This implies that your collections will certainly rely on your initialization value.
For even more details on K-Means and other kinds of without supervision learning formulas, check out my various other blog: Clustering Based Unsupervised Discovering Semantic network is one of those buzz word formulas that everyone is looking in the direction of these days. While it is not feasible for me to cover the detailed details on this blog site, it is essential to recognize the basic devices as well as the idea of back proliferation and vanishing gradient.
If the situation research study need you to build an expository version, either pick a different design or be prepared to explain just how you will certainly find how the weights are contributing to the final result (e.g. the visualization of surprise layers during image acknowledgment). Lastly, a solitary design may not accurately figure out the target.
For such situations, a set of numerous designs are utilized. An instance is provided below: Below, the designs are in layers or heaps. The output of each layer is the input for the following layer. One of one of the most common method of reviewing version performance is by determining the percent of records whose documents were predicted precisely.
Right here, we are wanting to see if our version is also complicated or otherwise complex sufficient. If the version is simple sufficient (e.g. we determined to utilize a straight regression when the pattern is not straight), we finish up with high bias and low variation. When our design is as well intricate (e.g.
Machine Learning Case Studies
High variance due to the fact that the outcome will certainly VARY as we randomize the training information (i.e. the version is not really steady). Currently, in order to figure out the version's intricacy, we utilize a learning curve as shown listed below: On the knowing curve, we vary the train-test split on the x-axis and compute the accuracy of the version on the training and recognition datasets.
Coding Practice
The additional the curve from this line, the greater the AUC and better the version. The highest possible a version can obtain is an AUC of 1, where the curve forms a right tilted triangular. The ROC curve can also help debug a design. For example, if the bottom left corner of the contour is more detailed to the random line, it indicates that the version is misclassifying at Y=0.
Additionally, if there are spikes on the contour (rather than being smooth), it suggests the design is not steady. When handling fraudulence versions, ROC is your buddy. For more details check out Receiver Operating Characteristic Curves Demystified (in Python).
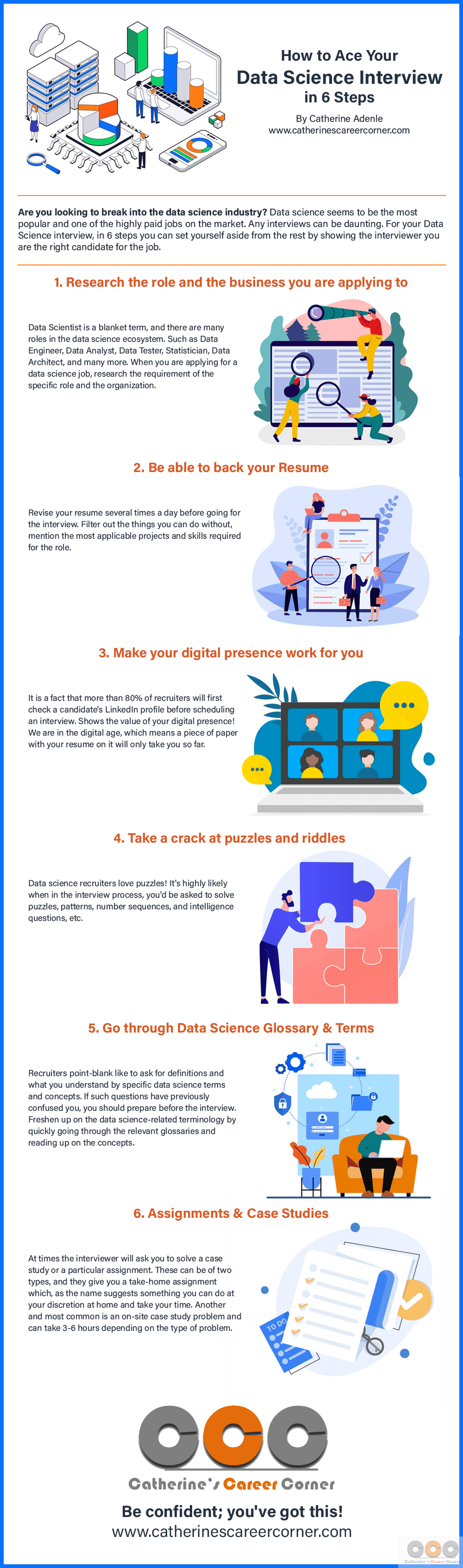
Data science is not simply one field yet a collection of fields used together to build something distinct. Information scientific research is simultaneously mathematics, data, problem-solving, pattern finding, interactions, and service. As a result of how wide and interconnected the area of information scientific research is, taking any kind of action in this field may appear so complex and difficult, from attempting to discover your method through to job-hunting, looking for the appropriate role, and finally acing the interviews, but, in spite of the intricacy of the area, if you have clear steps you can follow, entering into and obtaining a job in information scientific research will certainly not be so perplexing.
Data science is all concerning mathematics and statistics. From possibility concept to straight algebra, mathematics magic enables us to recognize data, discover fads and patterns, and construct algorithms to predict future data scientific research (mock data science interview). Mathematics and data are vital for information science; they are always inquired about in information science interviews
All skills are utilized daily in every data scientific research project, from data collection to cleaning to expedition and analysis. As quickly as the interviewer tests your ability to code and think of the various algorithmic issues, they will certainly offer you information science troubles to examine your data dealing with abilities. You typically can choose Python, R, and SQL to clean, discover and evaluate an offered dataset.
Building Career-specific Data Science Interview Skills
Maker knowing is the core of many data scientific research applications. Although you might be composing machine discovering formulas just sometimes at work, you require to be very comfy with the fundamental equipment finding out formulas. On top of that, you require to be able to recommend a machine-learning algorithm based upon a particular dataset or a details problem.
Excellent sources, including 100 days of maker discovering code infographics, and strolling with a device learning problem. Validation is just one of the main steps of any data science task. Making sure that your model behaves properly is important for your business and customers because any type of error might create the loss of cash and resources.
Resources to assess validation consist of A/B screening meeting inquiries, what to avoid when running an A/B Examination, type I vs. kind II errors, and guidelines for A/B tests. In addition to the inquiries regarding the details building blocks of the area, you will always be asked general information science concerns to evaluate your capability to put those structure obstructs together and create a full task.
The data science job-hunting procedure is one of the most difficult job-hunting processes out there. Looking for work roles in data science can be tough; one of the primary factors is the ambiguity of the function titles and summaries.
This ambiguity just makes planning for the interview also more of a headache. Nevertheless, just how can you prepare for an obscure function? Nonetheless, by practising the standard foundation of the area and after that some basic questions concerning the various algorithms, you have a durable and powerful mix guaranteed to land you the task.
Obtaining prepared for information science interview inquiries is, in some areas, no various than preparing for a meeting in any type of various other market.!?"Information scientist meetings consist of a whole lot of technological topics.
Best Tools For Practicing Data Science Interviews
, in-person meeting, and panel interview.
Technical abilities aren't the only kind of information scientific research interview concerns you'll run into. Like any type of interview, you'll likely be asked behavior questions.
Here are 10 behavior inquiries you could come across in a data scientist meeting: Inform me regarding a time you utilized data to bring about alter at a job. What are your leisure activities and passions outside of data scientific research?
Recognize the different sorts of meetings and the total procedure. Dive right into statistics, possibility, theory screening, and A/B testing. Master both fundamental and sophisticated SQL questions with sensible troubles and simulated meeting concerns. Make use of crucial collections like Pandas, NumPy, Matplotlib, and Seaborn for information adjustment, evaluation, and fundamental maker understanding.
Hi, I am currently planning for a data scientific research meeting, and I've discovered a rather tough question that I could make use of some aid with - Preparing for Technical Data Science Interviews. The question includes coding for an information science issue, and I believe it calls for some advanced abilities and techniques.: Provided a dataset including information about client demographics and acquisition background, the job is to forecast whether a customer will certainly purchase in the next month
Practice Interview Questions
You can not execute that action right now.
Wondering 'Exactly how to prepare for data scientific research interview'? Continue reading to locate the solution! Source: Online Manipal Take a look at the task listing extensively. See the firm's official website. Analyze the competitors in the market. Understand the firm's values and society. Check out the business's most recent success. Discover your potential recruiter. Before you dive right into, you should know there are particular sorts of interviews to get ready for: Interview TypeDescriptionCoding InterviewsThis meeting examines knowledge of various subjects, including equipment knowing strategies, useful information removal and adjustment challenges, and computer technology principles.
{kind=link}
Table of Contents
Latest Posts
Tech Interview Handbook: A Technical Interview Guide For Busy Engineers
How To Crack The Front-end Developer Interview – Tips For Busy Engineers
The Best Websites For Practicing Data Science Interview Questions
More
Latest Posts
Tech Interview Handbook: A Technical Interview Guide For Busy Engineers
How To Crack The Front-end Developer Interview – Tips For Busy Engineers
The Best Websites For Practicing Data Science Interview Questions